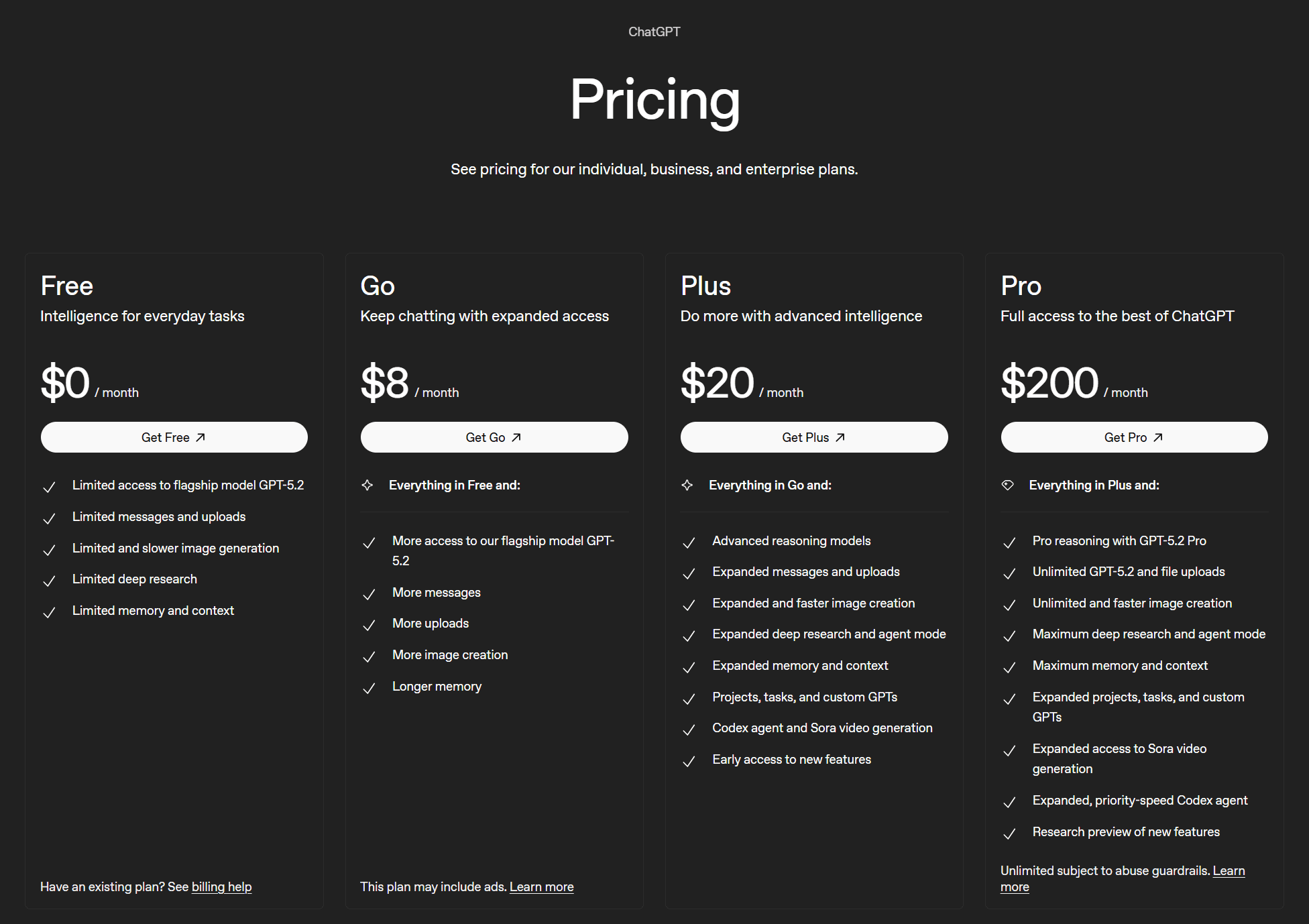
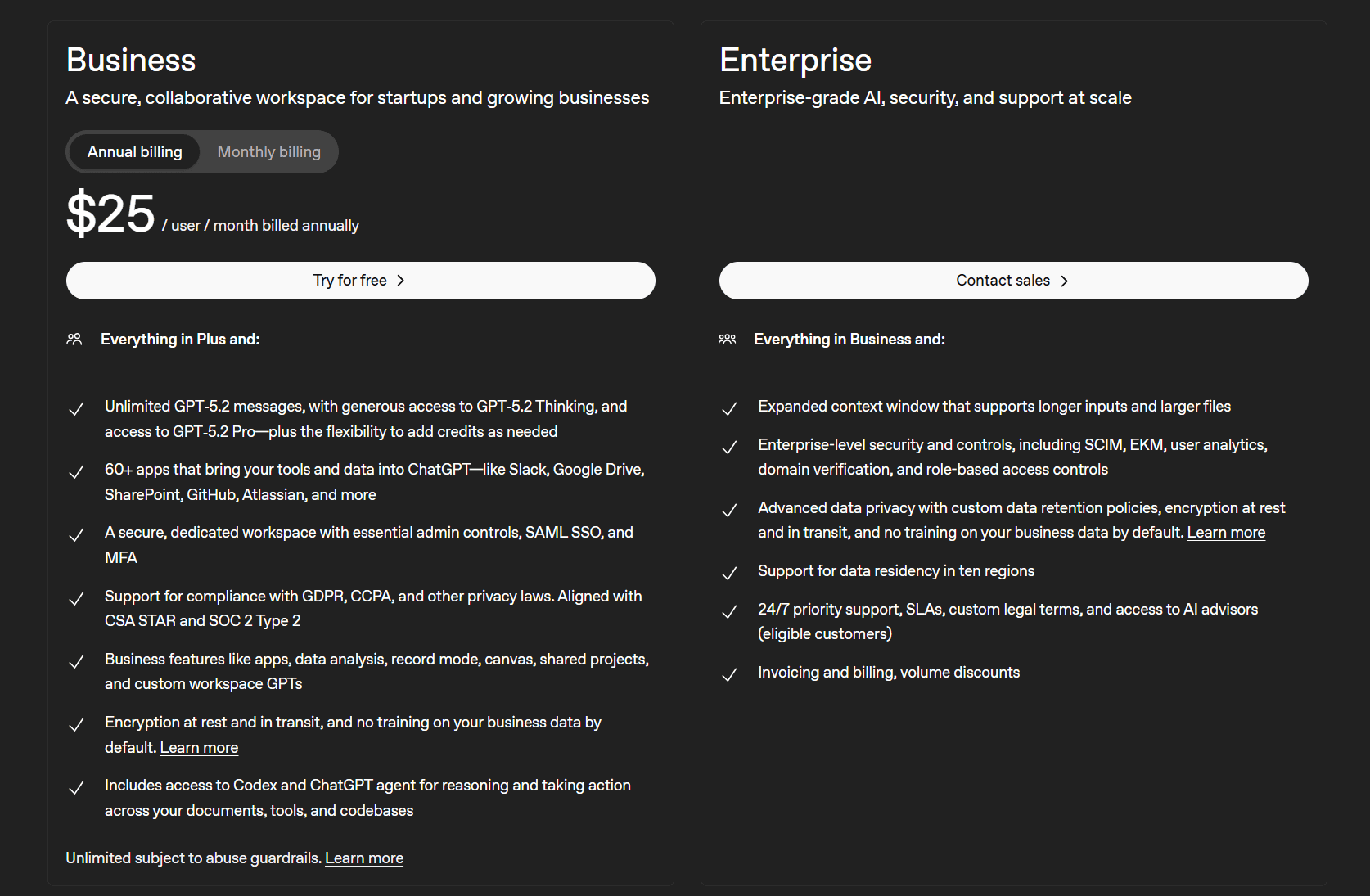
ChatGPT Record – ユーザーはChatGPTに会議の録音と文字起こしをさせ、メモや要約を作成させたり、会議で取り上げられたトピックについてLLMに質問したりすることができます。これは便利ですが、次のような専用のAIノートテイカーには及びません。 tl;dvのような専用のAIノートテイカーには及びません。
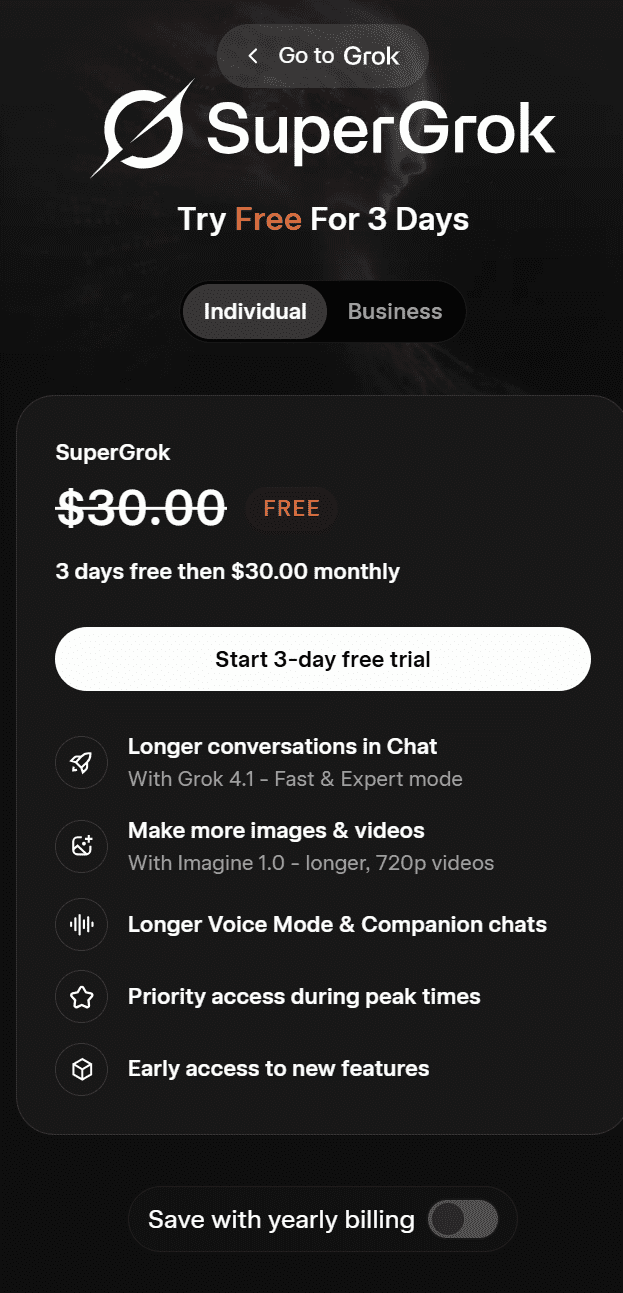
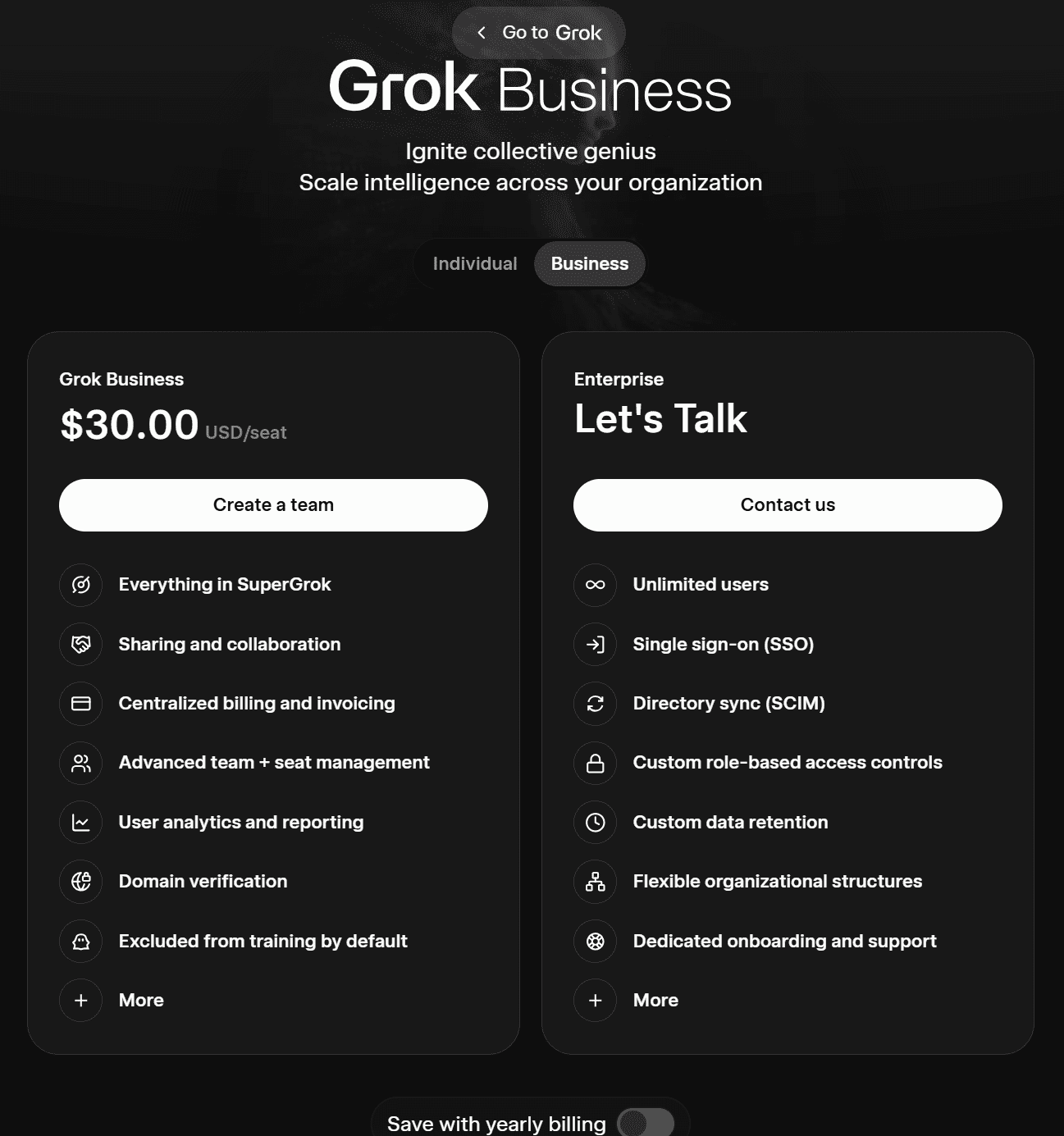
とはいえ、品質には微妙な差があります。個人的にはChatGPTの出力の方が優れていると思います。ChatGPTが考案したキャッチコピー「Work deeply. Collaborate clearly. Move faster.」は、特に素晴らしいというわけではありませんが、Grokの「Async work that gets things done」よりは断然マシです。
ChatGPTのブランドストーリーもわずかに優れていますが、その差はさほど大きくありません。同様に、その中核となる価値観も少し明確です。例えば、ChatGPTは「Clarity over noise(雑音よりも明快さを)」と述べていますが、Grokは単に「Clarity(明快さ)」とだけ述べています。
 コンテンツへスキップ
コンテンツへスキップ